Uniform interface blocks (cbuffers in hlsl) have unintuitive alignment rules where block members can’t cross 16-byte boundaries and each array element must be aligned to 16 bytes.
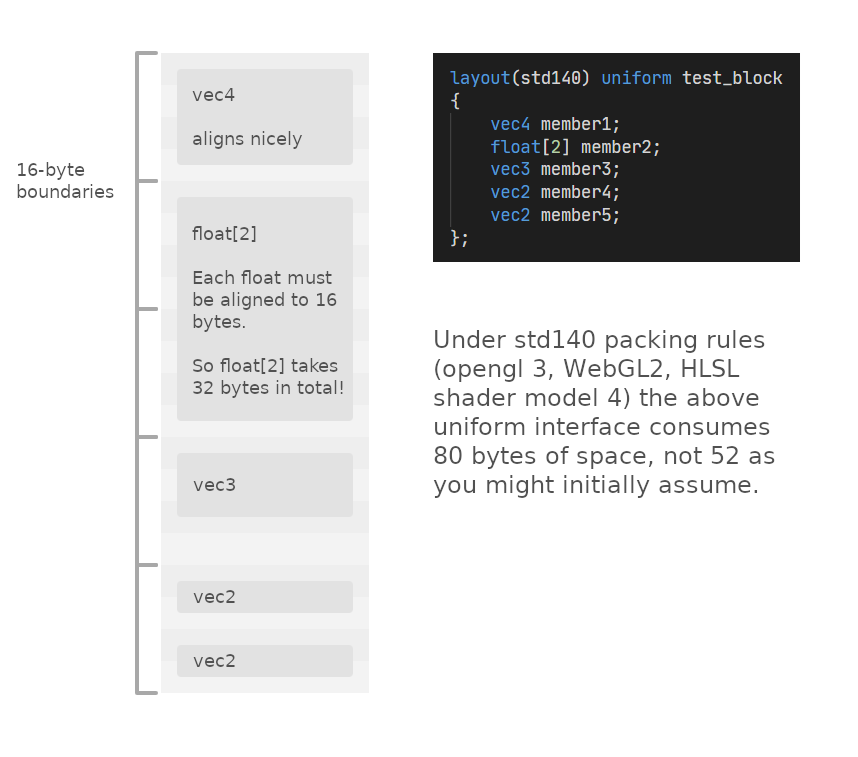
Manually packing data according to these rules is error prone as it’s easy to forget about some of the finer points of these rules (layout rules covers 2 pages in the OpenGL spec!) and adding, removing, or reorganising members can affect the alignment of following members.
I’m going to quickly cover how using spirv-cross, macros, and overloaded functions I generate abstracts at compile time from reflection data to handle all of this.
Spirv-Cross Reflection
At build time I compile my shaders to spirv bytecode using glslang, spirv-cross is then used to generate glsl code (for core 3.3 or ESSL) or shader model 5 HLSL. Spirv-cross also has facilities to output reflection data in a json format from the spirv file it reads in.
spirv-cross.exe input_vert.spv --stage --vert --extry main --reflect --output vert-reflection.json
spirv-cross.exe input_frag.spv --stage --frag --extry main --reflect --output frag-reflection.json
If we take the following fragment shader and look at the produced reflection data, we can see that spirv-cross has done most of the work for us!
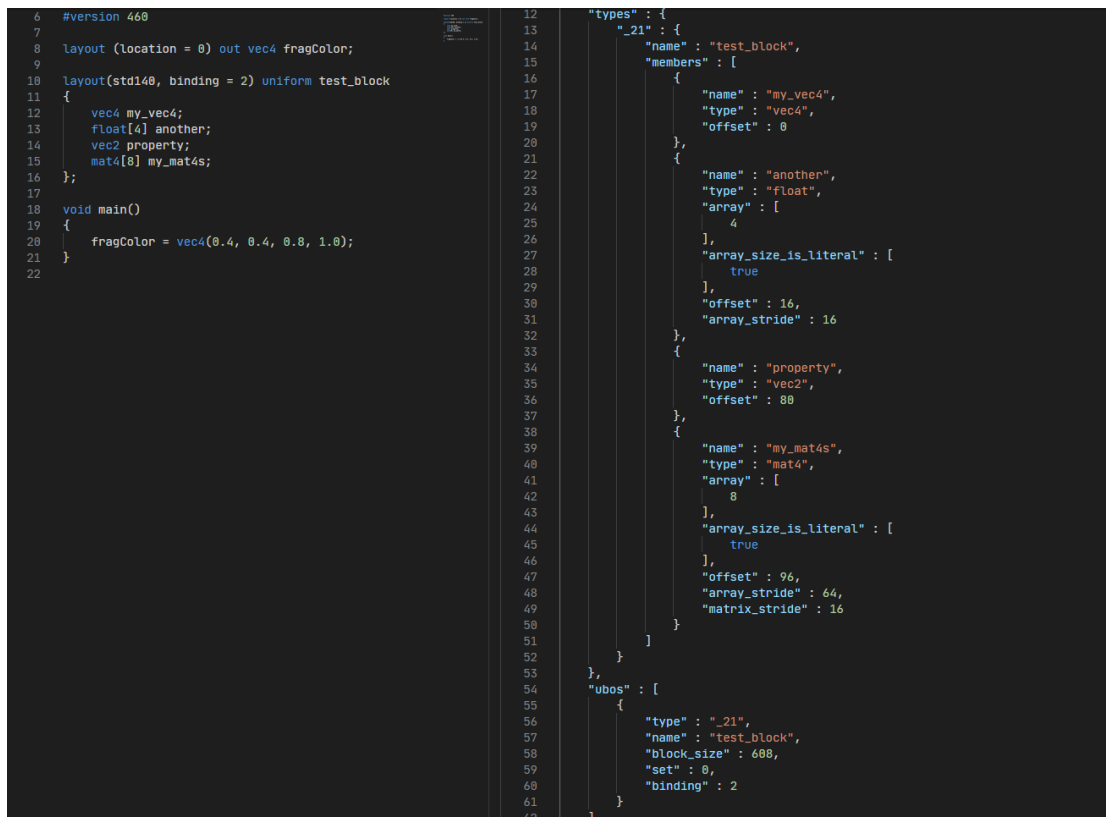
The reflection data lists all the buffer objects and its members, it also lists the total size of the buffer, offset of all members, and in the case of array types, the stride of each element in the array. From this reflection data I pull out the relevant parts and save it so it can be read by an initialisation macro.
In my engine I have a UniformBlob class, it contains a few fields, but the main thing of interest is that it holds a haxe.io.ArrayBufferView which you can write data into before its uploaded to the GPU.
Using the reflection data from spirv-cross we can generate abstracts around this type for every uniform interface for all shaders. Properties with setters are generated for each member in the interface block which handles writing the data to the correct offset location in the buffer.
Haxe 4.2 introduced overloaded functions for non-extern types, using these we can greatly simplify the macro code which will generate these abstracts. The UniformBlob type contains an overloaded write function for all the basic glsl types supported (bool, int, float, double, vecs, and mats), this way we don’t have to have a writeInt, writeFloat, writeVec2, etc and instead of looking at the glsl type in the macro and calling the correct function based on the type we can always all write and the compilers overload resolution will handle it all for us.
// Small excerpt of the overloads from the `UniformBlob` class.
// `buffer` is the `haxe.io.ArrayBufferView` for the raw data.
public extern inline overload function write(_offset : Int, _v : Bool)
{
final writer = Int32Array.fromData(buffer.getData());
writer[_offset] = if (_v) 1 else 0;
return _v;
}
public extern inline overload function write(_offset : Int, _v : Int)
{
final writer = Int32Array.fromData(buffer.getData());
writer[_offset] = _v;
}
public extern inline overload function write(_offset : Int, _v : Float)
{
final writer = Float32Array.fromData(buffer.getData());
writer[_offset] = _v;
}
public extern inline overload function write(_offset : Int, _v : Vec3)
{
final writer = Float32Array.fromData(buffer.getData());
final data = (cast _v : Vec3.Vec3Data);
writer[_offset + 0] = data.x;
writer[_offset + 1] = data.y;
writer[_offset + 2] = data.z;
return _v;
}
public extern inline overload function write(_offset : Int, _v : Mat4)
{
final data = (cast _v : Mat4.Mat4Data);
write(_offset + 0, data.c0);
write(_offset + 4, data.c1);
write(_offset + 8, data.c2);
write(_offset + 12, data.c3);
return _v;
}
For these overloaded write functions, the offset is not in bytes but instead the size of the type, so all we need to do in the macro is divide the bytes offset from spirv-cross by the size of the type to get the correct offset.
Abstract Generation
The name of the interface block is used as the basis for the abstract name and using the reflected total size we can generate an haxe.io.ArrayBufferView to fit the size exactly.
final name = buffer.name.toUpperCaseFirstChar();
final type : TypeDefinition = {
name : name,
pack : [],
kind : TDAbstract(macro : uk.aidanlee.flurry.api.gpu.shaders.UniformBlob, null, [ macro : uk.aidanlee.flurry.api.gpu.shaders.UniformBlob ]),
pos : Context.currentPos(),
fields : [
{
name : 'new',
pos : Context.currentPos(),
access : [ APublic, AInline ],
kind : FFun({
args : [],
expr : macro {
this = new uk.aidanlee.flurry.api.gpu.shaders.UniformBlob($v{ buffer.name }, new haxe.io.ArrayBufferView($v{ buffer.size }));
}
})
}
]
}
For non-array types it’s very easy to add a new property to the abstract, again using the member’s name as the name for the property. AlignedOffset is the byte offset divided by the type size (8 bytes for double, everything else is 4 bytes). Here you can see the overloads coming into play, no need to look at the glsl type, just convert to a complex type and call write, the compiler will figure the rest out.
final complexType = glslTypeToComplexType(member.type)
final alignedOffset = getAlignedOffset(member.type, member.offset);
type.fields.push({
name : member.name,
pos : Context.currentPos(),
access : [ APublic ],
kind : FProp('never', 'set', ct)
});
type.fields.push({
name : 'set_${ member.name }',
pos : Context.currentPos(),
access : [ APublic, AInline ],
kind : FFun({
args : [ { name: '_v', type: ct } ],
ret : ct,
expr : macro return this.write($v{ alignedOffset }, _v)
})
});
For glsl array types we convert them to a haxe array type, we then chain together a series of write calls where we start at the base offset and step forward by the stride for each loop iteration. Since arrays must be constant sized in uniform interfaces, we can check to make sure the provided haxe array is the correct size and unroll the loop in the macro code.
final complexType = glslTypeToComplexType(member.type)
final arrayCt = macro : Array<$ct>;
final chained = [ for (i in 0...member.size) {
final byteOffset = member.offset + (i * member.stride);
final alignedOffset = getAlignedOffset(member.type, byteOffset);
macro this.write($v{ alignedOffset }, _v[$v{ i }]);
} ];
type.fields.push({
name : member.name,
pos : Context.currentPos(),
access : [ APublic ],
kind : FProp('never', 'set', arrayCt)
});
type.fields.push({
name : 'set_${ member.name }',
pos : Context.currentPos(),
access : [ APublic, AInline ],
kind : FFun({
args : [ { name : '_v', type : arrayCt } ],
ret : arrayCt,
expr : macro {
if (_v.length != $v{ size })
{
throw new haxe.Exception('Haxe array does not match expected shader array size');
}
$b{ chained }
return _v;
}
})
});
I’m using the vector-math library for my maths types and those map onto glsl vector and matrix types, all the generated functions are inlined so they play nicely with vector-maths operations being inlined to avoid allocations.
Conclusion
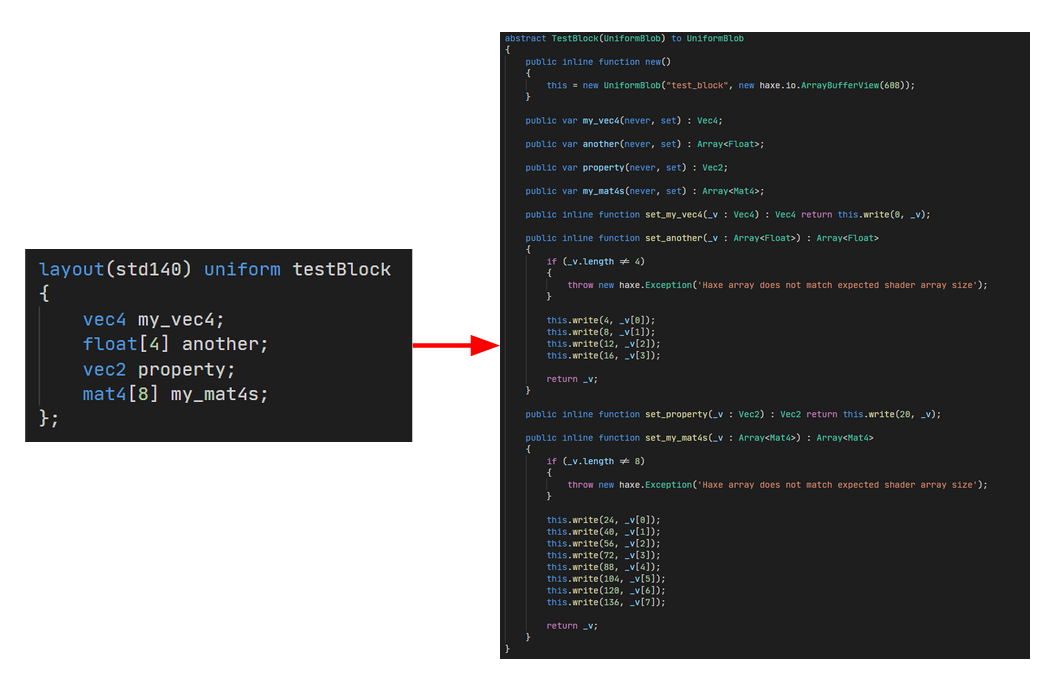
All the above stages (shader compilation, reflection, initialisation macro calls, caching) are handled automatically by my build tool so any changes made to shaders are automatically reflected in code. Its been really nice not having to deal with the hassle of uniform alignment and being able to get abstracts with properties which mirror the actual shader interface.
In the future I might add more abstract types for array types so you can partially update a uniform blob array type without having to re-assign the entire array.
Hopefully this gives some people ideas on how to improve working with shaders in code.